> INTELLIGENCE_EXPLOSION_PARAMETERS
These parameters control how the Intelligence Explosion curve evolves over time.
Probability Analysis
Intexp: 341 | CON: 98 | Ratio: 3.5:1

Probability Analysis
Intexp: 341 | CON: 98 | Ratio: 3.5:1
Recursive Self-Improvement
How effectively AI can improve itself once past the threshold. Higher values mean faster acceleration post-threshold. Like a snowball rolling downhill that gathers more snow - the bigger it gets, the faster it grows. As AI systems cross the threshold of being able to improve themselves, this parameter controls how effectively they can apply those improvements to make themselves even better at self-improvement.
Mathematical Effect:
At default (50): Factor of 5 applied to quadratic growth term
Productivity Increase in AI Research
Improvements in the efficiency and output of AI research teams, accelerating the development of more advanced systems. Like how construction equipment magnifies human physical capabilities, AI tools magnify research capabilities. As researchers gain access to better AI assistants, code generators, and data analysis tools, their productivity increases dramatically, leading to faster cycles of AI improvement.
Mathematical Effect:
Faster development cycles lead to more rapid capability gains
Unhobbling: CoT, ToT, MoE, Agents
Removing artificial limitations from AI systems, enabling more advanced reasoning, planning, and agent-based behaviors. Like taking the training wheels off a bicycle - the AI was always capable of moving faster, but was purposely constrained. As AI systems implement techniques like chain-of-thought, tree-of-thought, mixtures of experts, and agent-based architectures, they exhibit capabilities that were always latent in the models but needed specific techniques to unlock.

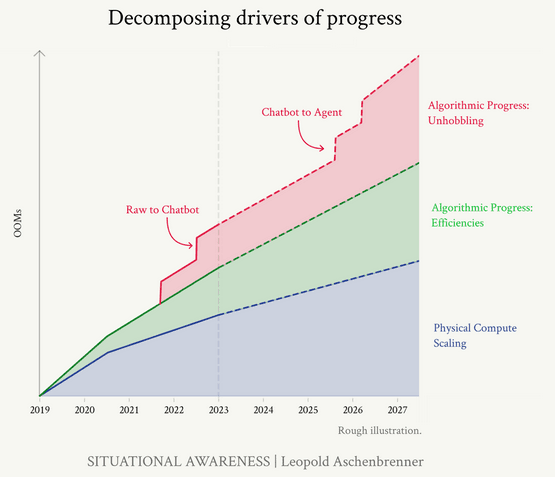
Mathematical Effect:
Sudden jumps in apparent intelligence as limitations are removed
Reinforcement Learning (Self-Play, Synthetic Data)
Progress in reinforcement learning and self-play techniques. Helps models improve through autonomous learning. Like how a chess player improves by playing against themselves, AI systems can improve through self-play without human intervention. This parameter controls how well systems can generate their own training experiences, create synthetic data, and learn from simulated environments, drastically reducing dependence on human-created datasets.
Mathematical Effect:
At default (50): Adds 0.8 IQ points/month linearly, plus creates exponential growth factor of 1.004 (0.4% compound growth)
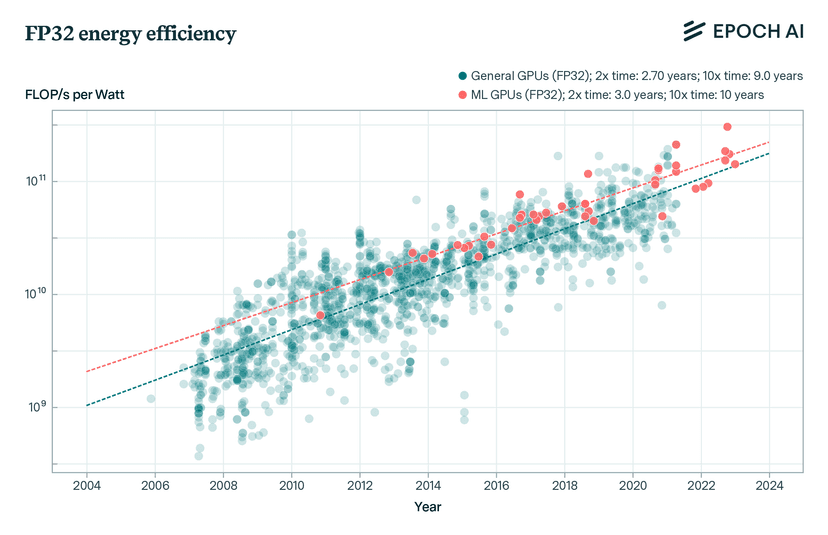
Compute Progress (More + Cheaper + More Energy Efficient)
Growth in compute resources available for AI training and inference. Represents both hardware advances and increased investment in computational infrastructure. Like how microprocessors have followed Moore's Law, AI compute capabilities continue to expand through better chips, larger data centers, and more efficient architectures. This parameter encompasses advances in specialized AI hardware, memory technologies, and the sheer scale of compute resources dedicated to AI.
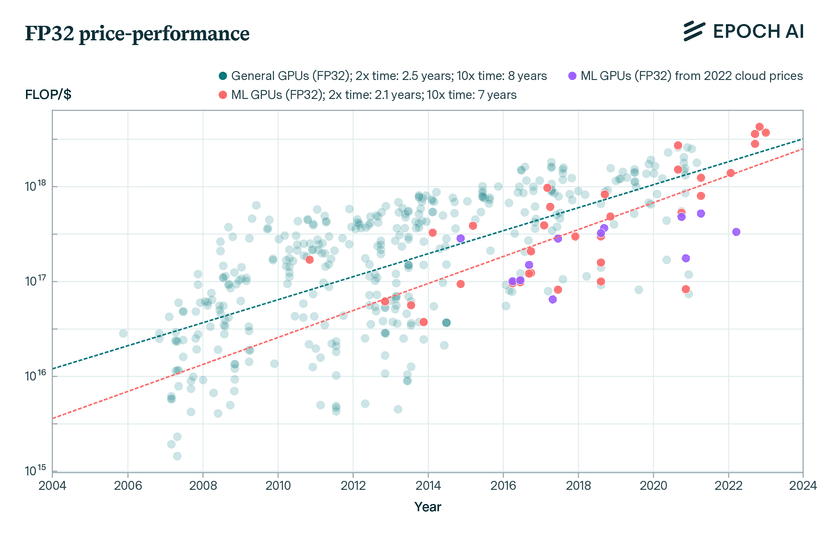
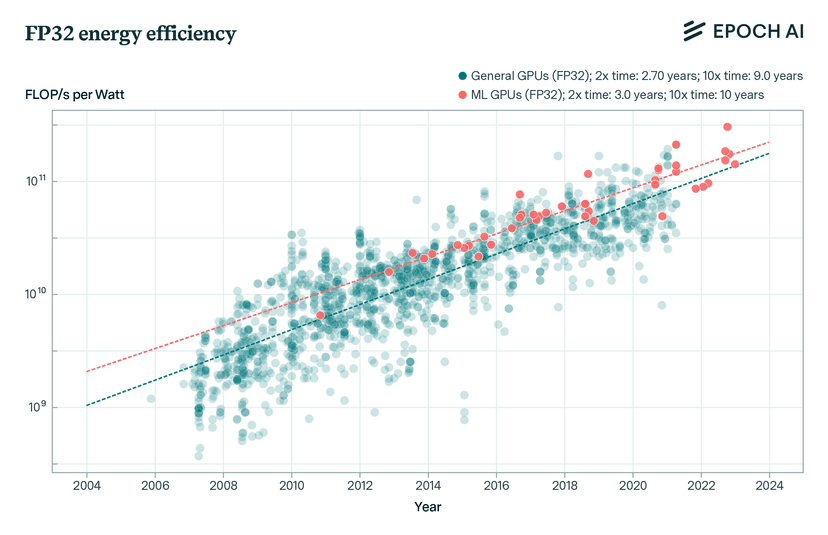
Mathematical Effect:
At default (50): Contributes 1.2 IQ points/month to linear growth rate
Algorithmic Progress
Rate of improvements in AI algorithm efficiency. Like improving a car's fuel efficiency - same hardware can do more with better algorithms. This parameter represents fundamental breakthroughs in how neural networks learn and generalize. Just as certain algorithmic improvements (like transformers) completely changed what was possible in AI, future improvements could similarly expand capabilities without requiring more compute.
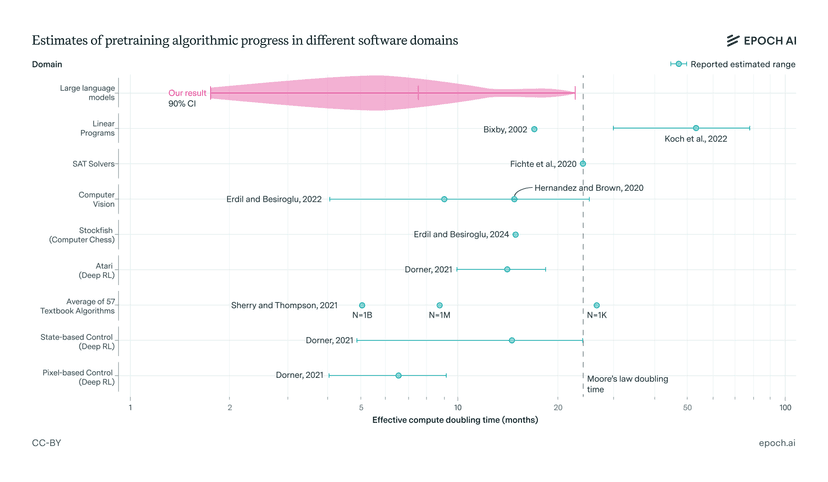
Mathematical Effect:
At default (50): Contributes 0.8 IQ points/month to linear growth rate
Compute Overhangs (Test-Time, Decentralized Training)
Untapped potential in existing hardware that could be leveraged for significant AI capability improvements through more efficient methods. Like finding a hidden gear in a machine that suddenly doubles its output. This parameter represents the discovery of techniques that extract much more capability from existing hardware, such as test-time optimizations, decentralized training, or innovative inference methods that maximize performance from current devices.
Mathematical Effect:
Allows unexpected breakthroughs without new hardware
Scaling Laws
How well intelligence scales with model size and compute. Higher values indicate better-than-expected scaling properties. Like how certain chemical reactions suddenly become self-sustaining above a critical mass. This parameter controls how effectively additional compute and model size translate into higher intelligence. If scaling laws remain power-law positive for longer than expected, intelligence gains could accelerate dramatically with scale.

Mathematical Effect:
At default (50): Contributes 0.8 IQ points/month to linear growth rate
Private-Public Delta
Difference between private and public model capabilities. Higher values indicate private models are significantly ahead of publicly disclosed ones. Like an iceberg, where only the tip is visible above water but much more exists below. This parameter represents the gap between AI systems that companies publicly release and their cutting-edge internal systems. A larger gap means what we see in public significantly underestimates true state-of-the-art capabilities.

Mathematical Effect:
At default (50): +10 IQ points to all historical data
New ML Paradigms (Post-Transformer)
Breakthroughs in ML architecture or training methods. Creates a discontinuous jump in AI capabilities. Like the leap from flip phones to smartphones - an entirely new paradigm emerges. This parameter represents revolutionary new approaches to machine learning beyond transformers, such as neuromorphic computing, quantum machine learning, or completely novel architectures that redefine what's possible in AI systems.
Mathematical Effect:
Adds up to 20 IQ points as an immediate jump at the present time
Inference Time Scaling
Improvements in models' thinking and reasoning processes. Longer inference time allows AIs to refine their answers through multiple reasoning steps, leading to higher quality, more intelligent responses. Like how humans can give better answers when they have more time to think. This parameter controls how effectively AI systems can use additional processing time to improve output quality through techniques like deliberate reasoning, verification steps, and iterative refinement.
Mathematical Effect:
At default (50): Contributes 0.4 IQ points/month to linear growth rate
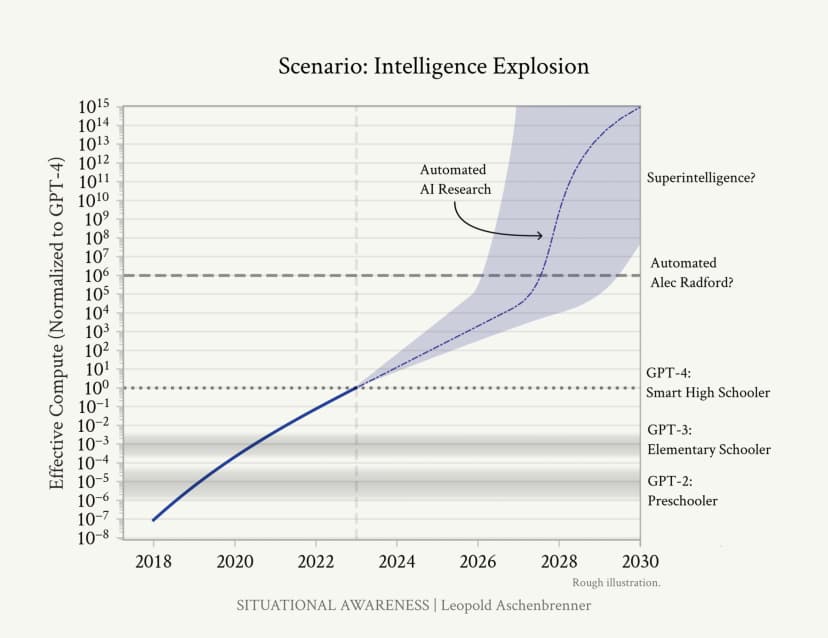
Unlocked Automated AI Research
IQ threshold at which AI can meaningfully improve AI research. Triggers recursive self-improvement. Like a rocket reaching escape velocity - once this threshold is crossed, a qualitatively different dynamic begins. This parameter defines the intelligence level at which AI systems can effectively participate in and accelerate their own development, creating a feedback loop of increasingly rapid improvement without human bottlenecks.
Mathematical Effect:
Default (180): Acceleration only begins after crossing this threshold